Java 学习-多线程-02 1.为什么使用线程池,解释一下线程池参数 为什么使用线程池:
创建和销毁现场需要消耗系统资源,线程池可以复用已创建的线程 。
控制并发的数量 。并发数量过多,可能会消耗过的的资源,从而造成服务器崩溃。(主要原因)可以对线程做同一管理。
参数:Executor接口,ThreadPoolExecutor是这个接口的实现类。ThreadPoolExecutor一共由四个构造方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
总共设计到 5 ~ 7 个参数,其中 5 个必要参数:
int corePoolSize: 该线程池中核心线程 数最大值
核心线程:线程池中有两类线程,核心线程和非核心线程。核心线程默认情况下会一直存在于线程池中,即使这个核心线程什么都不干,而非核心线程如果长时间闲置,就会被销毁。
int maximumPoolSize: 该线程池中线程总数 最大值。
等于核心线程数+非核心线程数。
int keepAliveTime: 非核心线程闲置超时时长
非核心线程如果处于闲置状态超过该值,就会被销毁。如果设置 allowCoreThreadTimeOut(true),则会也作用于核心线程。如果非核心线程闲置超过 keepAliveTime,就会被销毁。
TimeUnit unit: keepAliveTime 的时间单位
MICROSECONDS
BlockingQueue workQueue: 阻塞队列,维护着等待执行的 Runnable 任务对象。
常见的几个阻塞队列:
LinkedBlockingQueue
ArrayBlockingQueue
SynchronousQueue
DelayQueue
2 个非必要参数:
ThreadFactory threadFactory:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 static class DefaultThreadFactory implements ThreadFactory {SecurityManager s = System.getSecurityManager();null ) ? s.getThreadGroup() :"pool-" +"-thread-" ;
RejectedExecutionHandler handler:
ThreadPoolExecutor.AbortPolicy: 默认拒绝处理策略,丢弃任务并抛出RejectedExecutionException异常。ThreadPoolExecutor.DiscardPolicy: 丢弃任务,但是不抛出异常。ThreadPoolExecutor.DiscardOldestPolicy: 丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)。ThreadPoolExecutor.CallerRunsPolicy: 由调用线程处理该任务。
2.简述线程池处理流程 处理任务的核心方法是 execute
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public void execute (Runnable command) {if (command == null )throw new NullPointerException ();int c = ctl.get();if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true ))return ;if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))else if (workerCountOf(recheck) == 0 )null , false );else if (!addWorker(command, false ))
ctl.get()是获取线程池状态,用 int类型表示。第二步中,入队前进行了一次 isRunning判断,入队之后,又进行了一次 isRunning判断。
为什么要二次检查线程池的状态? 倘若没有二次检查,万一线程池处于非RUNNING状态(在多线程环境下很有可能发生),那么command永远不会执行。
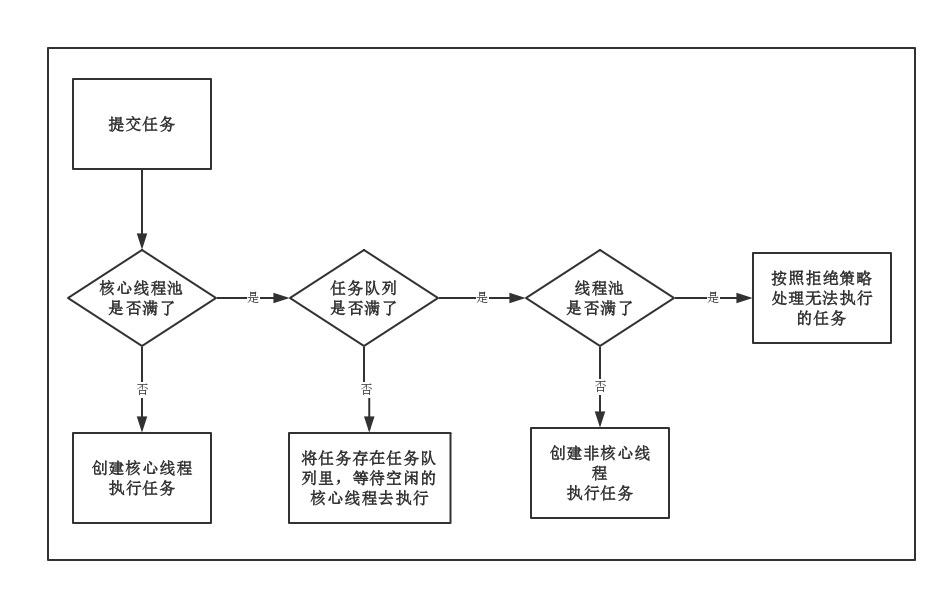
流程总结:
线程总数量 < corePoolSize,无论线程是否空闲,都会新建一个核心线程执行任务(让核心线程数量快速达到corePoolSize,在核心线程数量 < corePoolSize时)。注意,这一步需要获得全局锁。
线程总数量 >= corePoolSize时,新来的线程任务会进入任务队列中等待,然后空闲的核心线程会依次去缓存队列中取任务来执行(体现了线程复用)。
当缓存队列满了,说明这个时候任务已经多到爆棚,需要一些“临时工”来执行这些任务了。于是会创建非核心线程去执行这个任务。注意,这一步需要获得全局锁。
缓存队列满了, 且总线程数达到了maximumPoolSize,则会采取上面提到的拒绝策略进行处理。
整个过程如图所示:
3.线程池中阻塞队列的作用,为什么时先添加队列而不是先创建最大线程数?
作用: 为什么先添加队列而不是先创建最大线程数?
4.线程池中线程复用的原理 ThreadPoolExecutor在创建线程时,会将线程封装成工作线程worker ,并放入工作线程组中,然后这个worker反复从阻塞队列中拿任务去执行。
这里的 addWorker方法是在上面提到的 execute方法里面调用的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 private boolean addWorker (Runnable firstTask, boolean core) {for (;;) {int c = ctl.get();int rs = runStateOf(c);if (rs >= SHUTDOWN &&null &&return false ;for (;;) {int wc = workerCountOf(c);if (wc >= CAPACITY ||return false ;if (compareAndIncrementWorkerCount(c))break retry;if (runStateOf(c) != rs)continue retry;
上半部分主要是判断线程数量是否超出阈值,超过了就返回false。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 boolean workerStarted = false ;boolean workerAdded = false ;Worker w = null ;try {new Worker (firstTask);final Thread t = w.thread;if (t != null ) {final ReentrantLock mainLock = this .mainLock;try {int rs = runStateOf(ctl.get());if (rs < SHUTDOWN ||null )) {if (t.isAlive()) throw new IllegalThreadStateException ();int s = workers.size();if (s > largestPoolSize)true ;finally {if (workerAdded) {true ;finally {if (! workerStarted)return workerStarted;
创建 worker对象,并初始化一个 Thread对象,然后启动这个线程对象。
Worker类部分源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private final class Worker extends AbstractQueuedSynchronizer implements Runnable {final Thread thread;1 ); this .firstTask = firstTask;this .thread = getThreadFactory().newThread(this );public void run () {this );
Worker类实现了 Runnable接口,所以 Worker也是一个线程任务。在构造方法中,创建了一个线程,线程的任务就是自己。故 addWorker方法调用 addWorker方法源码下半部分中的第4步 t.start,会触发 Worker类的 run方法被JVM调用。
runWorker的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 final void runWorker (Worker w) {Thread wt = Thread.currentThread();Runnable task = w.firstTask;null ;boolean completedAbruptly = true ;try {while (task != null || (task = getTask()) != null ) {if ((runStateAtLeast(ctl.get(), STOP) ||try {Throwable thrown = null ;try {catch (RuntimeException x) {throw x;catch (Error x) {throw x;catch (Throwable x) {throw new Error (x);finally {finally {null ;false ;finally {
首先去执行创建这个 worker时就有的任务,当执行完这个任务后,worker的生命周期并没有结束,在 while循环中,worker会不断地调用 getTask方法从阻塞队列 中获取任务然后调用task.run()执行任务,从而达到复用线程的目的。只要 getTask方法不返回 null,此线程就不会退出。
当然,核心线程池中创建的线程想要拿到阻塞队列中的任务,先要判断线程池的状态,如果STOP 或者TERMINATED ,返回 null。
getTask方法的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 private Runnable getTask () {boolean timedOut = false ; for (;;) {int c = ctl.get();int rs = runStateOf(c);if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {return null ;int wc = workerCountOf(c);boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;if ((wc > maximumPoolSize || (timed && timedOut))1 || workQueue.isEmpty())) {if (compareAndDecrementWorkerCount(c))return null ;continue ;try {Runnable r = timed ?if (r != null )return r;true ;catch (InterruptedException retry) {false ;
核心线程的会一直卡在workQueue.take方法,被阻塞并挂起,不会占用CPU资源,直到拿到Runnable 然后返回(当然如果allowCoreThreadTimeOut 设置为true,那么核心线程就会去调用poll方法,因为poll可能会返回null,所以这时候核心线程满足超时条件也会被销毁)。
非核心线程会workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) ,如果超时还没有拿到,下一次循环判断compareAndDecrementWorkerCount 就会返回null,Worker对象的run()方法循环体的判断为null,任务结束,然后线程被系统回收 。